


In the previous blog – How to run an DeepStream application out-of-the-box on SmarteCAM, we got to know the process of starting to use SmarteCAM with DeepStream. Now, let’s see the YOLO object detection – one of the latest and fastest models.
Why YOLOV3?
You Only Look Once (YOLO) is one of the quickest real-time object detection algorithms (45 frames per second) when compared to the R-CNN family (R-CNN, Fast R-CNN, Faster R-CNN, etc.).
The R-CNN family of algorithms uses regions to localize the objects in images. Hence, the model is applied to multiple regions – and high-scoring regions of the image are considered as detected objects. But YOLO follows a completely different approach. Instead of selecting a few regions, it applies a neural network to the entire image and predicts bounding boxes, as well as their probabilities. This approach has made it become the most popular and fastest real-time object detection algorithm!
The default version of YOLOV3 supports the identification of 80 objects (people, dogs, cars, etc.). These models can be further improved to suit the requirements of specific applications.
Let’s look at how YOLOV3 can be run on e-con Systems’ SmarteCAM camera.
Necessary set-up for running YOLO
- Move to the YOLO folder $ cd /opt/nvidia/deepstream/deepstream-4.0/sources/objectDetector_Yolo
- Run the .sh file to load the model weights and config files
- $ ./prebuild.sh
- Export the CUDA version and run the make file
- $ export CUDA_VER=10.0
- $ make -C nvdsinfer_custom_impl_Yolo
- To run the application with samples videos
- $ deepstream-app -c deepstream_app_config_yoloV3_tiny.txt
- To run the application with our HDR camera, we need to make some changes in the config files. Open the model config file .txt
[source0]
enable=1
# Type – 1=CameraV4L2 2=URI 3=MultiURI
type=1
camera-width=640
camera-height=480
camera-fps-n=60
camera-fps-d=1
camera-v4l2-dev-node=0
num-sources=1
- Run the config file using deepstream-app
$ deepstream-app -c deepstream_app_config_yoloV3_tiny.txt
Note: Follow the same procedure for Yolo V3 and Yolo V2
Performance Analytics:
YOLOV3-Tiny runs at an average of 47 FPS with lower accuracy when compared to the full-fledged model.
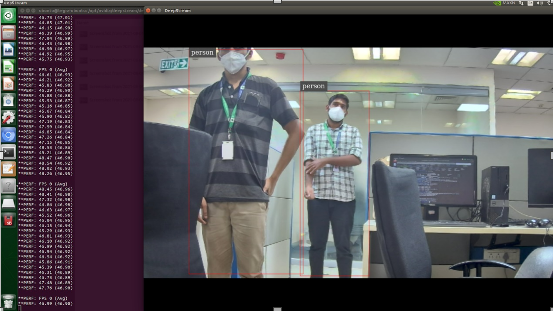
YOLOV3 runs at an average of 4 FPS with the highest accuracy.
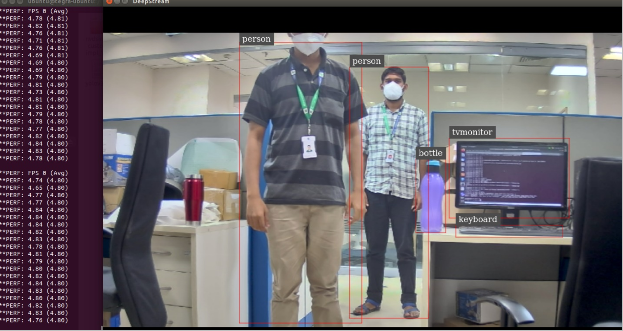
YOLOV3 FPS can be increased by changing model parameters in the config file. By default, the width and height
will be 608 x 608.
If you want to increase the V3 FPS, open Yolo V3.cfg file in location /opt/nvidia/deepstream/deepstream-4.0/sources/objectDetector_Yolo/yolov3.cfg and make the changes in [net] field before running it.
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=16
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
The result of 416 X 416 gives an average of 9 FPS but accuracy gets reduced.
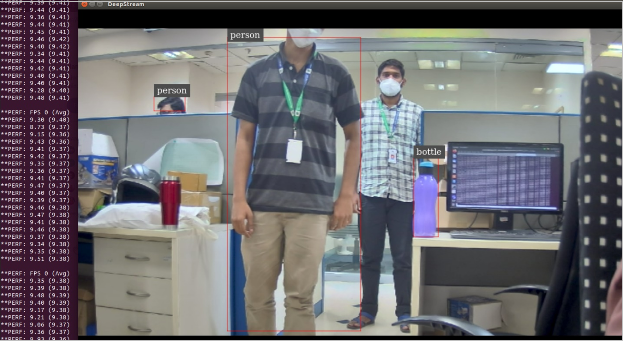
| Width and Height | FPS | Accuracy |
| 608 x 608 | 4 | High |
| 416 x 416 | 9 | Moderate |
| 320 x 320 | 15 | low |
The performance and FPS must be chosen wisely according to the end-user application.
For applications that require high accuracy over framerate (License Plate Recognition, Face Recognition, etc.), it is recommended to use the model input size as 608×608.
However, for applications requiring high framerate over accuracy, such as traffic monitoring systems, the 320×320 model input would be adequate.
To know more about the SmarteCAM, visit -> SmarteCAM or write to camerasolution@e-conststems.com.

Vimal Pachaiappan works as a Computer Vision Engineer at e-con Systems. He holds a master’s degree from Vellore Institute of Technology. With 5 years of experience in embedded vision solutions, he is specialized in computer vision, robotics, IoT, AWS and AI. Currently Vimal is developing Vision based AI applications, and assisting customers for camera solutions with his expertise throughout the product development cycle.